class: inverse, left, bottom background-image: url("img/back1.jpg") background-size: cover # **Data Visualization in R** ---- ## **<br/> library(ggplot2)** ### PhD. St. Orlando Joaqui-Barandica ### 2021 --- class: inverse, middle, center background-color: #C0392B <br><br> .center[ <img style="border-radius: 50%;" src="img/avatar.png" width="160px" href="https://www.joaquibarandica.com" /> ### [PhD. Student. Orlando Joaqui-Barandica](https://www.joaquibarandica.com) <br/> ### Universidad del Valle ] <br> .center[ *PhD. Student in Engineering with emphasis in Engineering Industrial* *MSc. Applied Economics* *BSc. Statistic* <i class="fas fa-link fa-spin "></i> [www.joaquibarandica.com](https://www.joaquibarandica.com) ] --- .pull-left[ <br><br><br><br><br> <img src="img/gif1.gif" width="110%" /> ] <br><br> .pull-right[ .center[ # Orlando Joaqui-Barandica ### [www.joaquibarandica.com](https://www.joaquibarandica.com) `Statistician and Master in Applied Economics from Universidad del Valle. He is currently a Ph.D. student in Engineering with an emphasis in Industrial Engineering. Teaching and research experience in the area of Statistics, Econometrics and Quantitative Finance in different recognized universities in the region such as Universidad del Valle, Pontificia Universidad Javeriana de Cali and Universidad ICESI. Research lines: Applied Statistics, Applied Econometrics, Quantitative Finance, Asset-Liability Management.` ] ] --- name: menu background-image: url("img/back2.jpg") background-size: cover class: left, middle, inverse # Contenido ---- .pull-left[ ### <i class="fa fa-project-diagram" role="presentation" aria-label="project-diagram icon"></i> [Tipos de gráficos](#Tipos) ### <i class="fa fa-sort-numeric-down" role="presentation" aria-label="sort-numeric-down icon"></i> [Univariados](#Univariados) ### <i class="fa fa-list-ol" role="presentation" aria-label="list-ol icon"></i> [Bivariados](#Bivariados) ### <i class="fab fa-buffer" role="presentation" aria-label="buffer icon"></i> [Multivariados](#Multi) ] .pull-right[ ### <i class="fa fa-map-marker-alt" role="presentation" aria-label="map-marker-alt icon"></i> [Maps](#Maps) ### <i class="fa fa-chart-line" role="presentation" aria-label="chart-line icon"></i> [Dependientes en el tiempo](#Time) ### <i class="fa fa-angle-double-right" role="presentation" aria-label="angle-double-right icon"></i> [Modelos Estadísticos](#Model) ] --- name: Tipos class: inverse, center, middle # <i class="fa fa-project-diagram" role="presentation" aria-label="project-diagram icon"></i> # Tipos de gráficos ---- .right[ .bottom[ #### [<i class="fa fa-bell" role="presentation" aria-label="bell icon"></i>](#menu) ] ] --- # Tipos de gráficos ---- > ### 1. Gráficos Univariados: Los gráficos univariados trazan la distribución de datos de una sola variable. La variable puede ser categórica (por ejemplo, raza, sexo) o cuantitativa (por ejemplo, edad, peso). <br> * **Cuantitativo:** La distribución de una sola variable cuantitativa generalmente se traza con un histograma, un diagrama de densidad de kernel o un diagrama de puntos. <br> * **Categórico:** La distribución de una sola variable categórica generalmente se traza con un gráfico de barras, un gráfico circular o (con menos frecuencia) un mapa de árbol. ---- --- # Tipos de gráficos ---- > ### 2. Gráficos Bivariados: Los gráficos bivariados muestran la relación entre dos variables. El tipo de gráfico dependerá del nivel de medición de las variables (categóricas o cuantitativas). <br> * **Categórico `vs` Categórico:** Al trazar la relación entre dos variables categóricas, normalmente se utilizan gráficos de barras apiladas, agrupadas o segmentadas. Un enfoque menos común es el gráfico de mosaico. * **Cuantitativo `vs` Cuantitativo:** La relación entre dos variables cuantitativas generalmente se muestra mediante diagramas de dispersión y gráficos de líneas. * **Categórico `vs` Cuantitativo:** Al trazar la relación entre una variable categórica y una variable cuantitativa, hay disponible una gran cantidad de tipos de gráficos. Estos incluyen gráficos de barras que utilizan estadísticas resumidas, gráficos de densidad de kernel agrupados, gráficos de caja uno al lado del otro, gráficos de violín uno al lado del otro, gráficos de media / sem, gráficos de crestas y gráficos de Cleveland. ---- --- # Tipos de gráficos ---- > ### 3. Gráficos Multivariados: Los gráficos multivariados muestran las relaciones entre tres o más variables. Hay dos métodos comunes para acomodar múltiples variables: agrupamiento y facetado (Parcelas). <br> * **Agrupación:** En la agrupación, los valores de las dos primeras variables se asignan a los ejes x y y. Luego, las variables adicionales se asignan a otras características visuales como el color, la forma, el tamaño, el tipo de línea y la transparencia. La agrupación le permite trazar los datos de varios grupos en un solo gráfico. <br> * **Facetas o Parcelas:** La agrupación le permite trazar múltiples variables en un solo gráfico, utilizando características visuales como el color, la forma y el tamaño. En el facetado, un gráfico consta de varios gráficos separados o pequeños múltiplos, uno para cada nivel de una tercera variable o combinación de variables. ---- --- # Tipos de gráficos ---- > ### 4. Mapas: R proporciona una gran variedad de métodos para crear mapas tanto estáticos como interactivos que contienen información estadística. Destacan librerías como ggmapy choroplethr. <br> * **Mapas de densidad de puntos:** Los mapas de densidad de puntos utilizan puntos en un mapa para explorar las relaciones espaciales. <br> * **Mapas de coropletas:** Los mapas de coropletas usan color o sombreado en áreas predefinidas para indicar valores promedio de una variable numérica en esa área. ---- --- # Tipos de gráficos ---- > ### 5. Dependientes en el tiempo: Un gráfico puede ser un vehículo poderoso para mostrar cambios a lo largo del tiempo. El gráfico dependiente del tiempo más común es el gráfico lineal de series de tiempo . Otras opciones incluyen los gráficos con mancuernas y el gráfico de pendiente. <br> * **Serie temporal:** Una serie de tiempo es un conjunto de valores cuantitativos obtenidos en puntos de tiempo sucesivos. Los intervalos entre puntos de tiempo (por ejemplo, horas, días, semanas, meses o años) suelen ser iguales. <br> * **Mancuernas (Dumbbell):** Los gráficos con mancuernas son útiles para mostrar cambios entre dos puntos de tiempo para varios grupos u observaciones. Se utiliza la función geom_dumbbell del paquete ggalt. <br> * **Pendiente:** Cuando hay varios grupos y varios puntos de tiempo, un gráfico de pendiente puede ser útil. <br> * **Área:** Un gráfico de área simple es básicamente un gráfico lineal, con un relleno desde la línea hasta el eje x. ---- --- # Tipos de gráficos ---- > ### 6. Modelos estadísticos: Un modelo estadístico describe la relación entre una o más variables explicativas y una o más variables de respuesta. Los gráficos pueden ayudar a visualizar estas relaciones. <br> * **Correlación:** Ayudan a visualizar las relaciones por pares entre un conjunto de variables cuantitativas al mostrar sus correlaciones usando color o sombreado. <br> * **Regresión Lineal:** Permite explorar la relación entre una variable de respuesta cuantitativa y una variable explicativa mientras que otras variables se mantienen constantes. <br> * **Regresión Logística:** Se puede utilizar para explorar la relación entre una variable de respuesta binaria y una variable explicativa mientras que otras variables se mantienen constantes. Las variables de respuesta binaria tienen dos niveles (sí / no, vivió / murió, pasa / no pasa, maligno / benigno). ---- --- # Tipos de gráficos ---- > ### 6. Modelos estadísticos: Un modelo estadístico describe la relación entre una o más variables explicativas y una o más variables de respuesta. Los gráficos pueden ayudar a visualizar estas relaciones. <br> * **Supervivencia:** La variable de respuesta es el tiempo hasta un evento. Esto suele ser cierto en la investigación de la salud, donde nos interesa el tiempo de recuperación, el tiempo de muerte o el tiempo de recaída. Si el evento no ha ocurrido para una observación (ya sea porque el estudio terminó o el paciente abandonó), se dice que la observación está censurada. <br> * **Mosaico:** Muestran la relación entre variables categóricas utilizando rectángulos cuyas áreas representan la proporción de casos para cualquier combinación de niveles dada. El color de los mosaicos también puede indicar la relación de grado entre las variables. ---- --- # Tipos de gráficos ---- > ### 7. Otros gráficos: <br> * **Dispersión 3D** * **Biplots** * **Burbujas** * **Diagramas de flujo** * **Mapas de calor** * **Radar** * **Matriz de dispersión** * **Cascada** * **Wordcloud** ---- --- name: Univariados class: inverse, center, middle # <i class="fa fa-sort-numeric-down" role="presentation" aria-label="sort-numeric-down icon"></i> # Gráficos Univariados ---- .right[ .bottom[ #### [<i class="fa fa-bell" role="presentation" aria-label="bell icon"></i>](#menu) ] ] --- name: Histograma # <i class="fa fa-sort-numeric-down" role="presentation" aria-label="sort-numeric-down icon"></i> Histograma .left-column[ Un histograma es una representación gráfica precisa de la distribución de una variable numérica. <br> Solo toma como entrada variables numéricas. <br> La variable se divide en varios contenedores y el número de observaciones por contenedor está representado por la altura de la barra. ] .right-column[ * Los histogramas se utilizan para estudiar la distribución de una o unas pocas variables. <br><br> * Verificar la distribución de sus variables una por una es probablemente la primera tarea que debe hacer cuando obtiene un nuevo conjunto de datos. <br><br> * Entrega una buena cantidad de información. <br><br> * El histograma permite comparar la distribución de algunas variables. <br><br> * No compare más de 3 o 4, haría que la figura fuera desordenada e ilegible. Esta comparación se puede hacer mostrando las 2 variables en el mismo gráfico y usando transparencia. ] --- # <i class="fa fa-sort-numeric-down" role="presentation" aria-label="sort-numeric-down icon"></i> Histograma ### Errores comunes .pull-left[ * Pruebe con varios tamaños de contenedor , puede llevar a conclusiones muy diferentes. * No uses una gamma de color extraño. No da más información. * No compare más de ~ 3 grupos en el mismo histograma. El gráfico se vuelve desordenado y difícilmente comprensible. En su lugar, use una trama de violín, una trama de caja, una trama de cresta o use un múltiplo pequeño. * Usar anchos desiguales ] .pull-right[  **No lo confunda con un diagrama de barras**. `Un diagrama de barras da un valor para cada grupo de una variable categórica. Aquí, solo tenemos una variable numérica y cambiamos su distribución.` ] --- # <i class="fa fa-sort-numeric-down" role="presentation" aria-label="sort-numeric-down icon"></i> Histograma Usando el conjunto de datos `Marriage` examinemos las edades de los participantes de la boda. .pull-left[ ```r # Libraries library(ggplot2) data(Marriage, package = "mosaicData") # plot the age distribution using a histogram ggplot(Marriage, aes(x = age)) + geom_histogram() + labs(title = "Participants by age", x = "Age") ``` `La mayoría de los participantes parecen tener poco más de veinte años con otro grupo de cuarenta y un grupo mucho más pequeño de sesenta y setenta. Esta sería una distribución multimodal.` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-sort-numeric-down" role="presentation" aria-label="sort-numeric-down icon"></i> Histograma Los colores del histograma se pueden modificar usando dos opciones: .pull-left[ ```r # Libraries library(ggplot2) data(Marriage, package = "mosaicData") ggplot(Marriage, aes(x = age)) + geom_histogram(fill = "cornflowerblue", color = "white") + labs(title="Participants by age", x = "Age") ``` * `fill` color de relleno para las barras * `color` color del borde de las barras ] .pull-right[ <!-- --> ] --- # <i class="fa fa-sort-numeric-down" role="presentation" aria-label="sort-numeric-down icon"></i> Histograma .pull-left[ Una de las opciones de histograma más importantes es `bins`, que controla el número de contenedores en los que se divide la variable numérica (es decir, el número de barras en el gráfico). El valor predeterminado es 30, pero es útil probar números cada vez más pequeños para tener una mejor impresión de la forma de la distribución. ```r # plot the histogram with 20 bins library(ggplot2) data(Marriage, package = "mosaicData") ggplot(Marriage, aes(x = age)) + geom_histogram(fill = "cornflowerblue", color = "white", bins = 20) + labs(title="Participants by age", subtitle = "number of bins = 20", x = "Age") ``` > Alternativamente, puede especificar el ancho `binwidth` de los contenedores representados por las barras. ] .pull-right[ <!-- --> ] --- # <i class="fa fa-sort-numeric-down" role="presentation" aria-label="sort-numeric-down icon"></i> Histograma .pull-left[ El eje y puede representar recuentos o porcentaje del total. ```r # plot the histogram with percentages on the y-axis library(ggplot2) data(Marriage, package = "mosaicData") library(scales) ggplot(Marriage, aes(x = age, y= ..count.. / sum(..count..))) + geom_histogram(fill = "cornflowerblue", color = "white", binwidth = 5) + labs(title="Participants by age", y = "Percent", x = "Age") + scale_y_continuous(labels = percent) ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-sort-numeric-down" role="presentation" aria-label="sort-numeric-down icon"></i> Histograma .pull-left[ ```r # Libraries library(tidyverse) library(hrbrthemes) library(viridis) # Load dataset from github data <- read.table("https://raw.githubusercontent.com/holtzy/data_to_viz/master/Example_dataset/1_OneNum.csv", header=TRUE) # Make the histogram data %>% filter( price<300 ) %>% ggplot( aes(x=price)) + stat_bin(breaks=seq(0,300,10), fill="#69b3a2", color="#e9ecef", alpha=0.9) + ggtitle("Night price distribution of Airbnb appartements") + theme_ipsum() ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-sort-numeric-down" role="presentation" aria-label="sort-numeric-down icon"></i> Histograma ### Comparación de Distribuciones .pull-left[ ```r # Build dataset with different distributions data <- data.frame( type = c( rep("edge peak", 1000), rep("comb", 1000), rep("normal", 1000), rep("uniform", 1000), rep("bimodal", 1000), rep("skewed", 1000) ), value = c( rnorm(900), rep(3, 100), rnorm(360, sd=0.5), rep(c(-1,-0.75,-0.5,-0.25,0,0.25,0.5,0.75), 80), rnorm(1000), runif(1000), rnorm(500, mean=-2), rnorm(500, mean=2), abs(log(rnorm(1000))) ) ) # Represent it data %>% ggplot( aes(x=value)) + geom_histogram(fill="#69b3a2", color="#e9ecef", alpha=0.9) + facet_wrap(~type, scale="free_x") + theme_ipsum() + theme( panel.spacing = unit(0.1, "lines"), axis.title.x=element_blank(), axis.text.x=element_blank(), axis.ticks.x=element_blank() ) ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-sort-numeric-down" role="presentation" aria-label="sort-numeric-down icon"></i> Histograma ### Comparación de Distribuciones .pull-left[ ```r # Build dataset with different distributions data <- data.frame( type = c( rep("variable 1", 1000), rep("variable 2", 1000) ), value = c( rnorm(1000), rnorm(1000, mean=4) ) ) # Represent it data %>% ggplot( aes(x=value, fill=type)) + geom_histogram( color="#e9ecef", alpha=0.6) + scale_fill_manual(values=c("#69b3a2", "#404080")) + theme_ipsum() + labs(fill="") ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-sort-numeric-down" role="presentation" aria-label="sort-numeric-down icon"></i> Histograma ### Histograma espejo .pull-left[ ```r data <- data.frame( x = rnorm(1000), y = rnorm(1000, mean=2) ) data %>% ggplot( aes(x) ) + geom_histogram( aes(x = x, y = ..density..), binwidth = diff(range(data$x))/30, fill="#69b3a2" ) + geom_label( aes(x=4.8, y=0.25, label="variable1"), color="#69b3a2") + geom_histogram( aes(x = y, y = -..density..), binwidth = diff(range(data$x))/30, fill= "#404080") + geom_label( aes(x=4.8, y=-0.25, label="variable2"), color="#404080") + theme_ipsum() + xlab("value of x") ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-sort-numeric-down" role="presentation" aria-label="sort-numeric-down icon"></i> Histograma ### Histograma base .pull-left[ ```r # Create data my_variable=rnorm(2000, 0 , 10) # Calculate histogram, but do not draw it my_hist=hist(my_variable , breaks=40 , plot=F) # Color vector my_color= ifelse(my_hist$breaks < -10, rgb(0.2,0.8,0.5,0.5) , ifelse (my_hist$breaks >=10, "purple", rgb(0.2,0.2,0.2,0.2) )) # Final plot plot(my_hist, col=my_color , border=F , main="" , xlab="value of the variable", xlim=c(-40,40) ) ``` ] .pull-right[ <!-- --> ] --- name: Densidad # <i class="fa fa-bacon" role="presentation" aria-label="bacon icon"></i> Densidad Una gráfica de densidad es una representación de la distribución de una variable numérica. Utiliza una estimación de densidad de kernel para mostrar la función de densidad de probabilidad de la variable. **Es una versión suavizada del histograma y se utiliza en el mismo concepto.** -- `La estimación de la densidad de kernel es un método no paramétrico de estimar la función de densidad de probabilidad (PDF) de una variable aleatoria continua. No es paramétrico porque no asume ninguna distribución subyacente para la variable. Esencialmente, en cada datum, se crea una función de kernel con el datum en su centro; esto asegura que el kernel sea simétrico con respecto al datum. Luego, el PDF se estima agregando todas estas funciones del kernel y dividiendo por la cantidad de datos para garantizar que satisfaga las 2 propiedades de un PDF:` `Cada valor posible del PDF (es decir, la función f (x)) no es negativo. La integral definida del PDF sobre su conjunto de soporte es igual a 1.` > Las gráficas de densidad se utilizan para estudiar la distribución de una o unas pocas variables. Verificar la distribución de sus variables una por una es probablemente la primera tarea que debe hacer cuando obtiene un nuevo conjunto de datos. Entrega una buena cantidad de información. --- # <i class="fa fa-bacon" role="presentation" aria-label="bacon icon"></i> Densidad Básicamente, estamos tratando de dibujar un histograma suavizado, donde el área debajo de la curva es igual a uno. .pull-left[ <br><br> ```r # Create a kernel density plot of age ggplot(Marriage, aes(x = age)) + geom_density() + labs(title = "Participants by age") ``` <br> > El gráfico muestra la distribución de puntuaciones. Por ejemplo, la proporción de casos entre 20 y 40 años estaría representada por el área bajo la curva entre 20 y 40 en el eje x. ] .pull-right[ <!-- --> ] --- # <i class="fa fa-bacon" role="presentation" aria-label="bacon icon"></i> Densidad .pull-left[ <br> > Al igual que con los gráficos anteriores, podemos usa `fill` y `color` para especificar los colores de relleno y borde. <br> ```r # Create a kernel density plot of age ggplot(Marriage, aes(x = age)) + geom_density(fill = "indianred3") + labs(title = "Participants by age") ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-bacon" role="presentation" aria-label="bacon icon"></i> Densidad ### Densidad una sola variable .pull-left[ ```r # Libraries library(tidyverse) library(hrbrthemes) library(viridis) # Load dataset from github data <- read.table("https://raw.githubusercontent.com/holtzy/data_to_viz/master/Example_dataset/1_OneNum.csv", header=TRUE) # Make the histogram data %>% filter( price<300 ) %>% ggplot( aes(x=price)) + geom_density(fill="#69b3a2", color="#e9ecef", alpha=0.8) + ggtitle("Night price distribution of Airbnb appartements") + theme_ipsum() ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-bacon" role="presentation" aria-label="bacon icon"></i> Densidad ### Comparar densidades .pull-left[ ```r # Build dataset with different distributions data <- data.frame( type = c( rep("edge peak", 1000), rep("comb", 1000), rep("normal", 1000), rep("uniform", 1000), rep("bimodal", 1000), rep("skewed", 1000) ), value = c( rnorm(900), rep(3, 100), rnorm(360, sd=0.5), rep(c(-1,-0.75,-0.5,-0.25,0,0.25,0.5,0.75), 80), rnorm(1000), runif(1000), rnorm(500, mean=-2), rnorm(500, mean=2), abs(log(rnorm(1000))) ) ) # Represent it data %>% ggplot( aes(x=value)) + geom_density(fill="#69b3a2", color="#e9ecef", alpha=0.9, adjust = 0.5) + facet_wrap(~type, scale="free") + theme_ipsum() + theme( panel.spacing = unit(0.1, "lines"), axis.title.x=element_blank(), axis.text.x=element_blank(), axis.ticks.x=element_blank() ) ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-bacon" role="presentation" aria-label="bacon icon"></i> Densidad ### Comparar densidades .pull-left[ ```r # Build dataset with different distributions data <- data.frame( type = c( rep("variable 1", 1000), rep("variable 2", 1000) ), value = c( rnorm(1000), rnorm(1000, mean=4) ) ) # Represent it data %>% ggplot( aes(x=value, fill=type)) + geom_density( color="#e9ecef", alpha=0.6) + scale_fill_manual(values=c("#69b3a2", "#404080")) + theme_ipsum() + labs(fill="") ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-bacon" role="presentation" aria-label="bacon icon"></i> Densidad ### Densidades espejo .pull-left[ ```r data <- data.frame( x = rnorm(1000), y = rnorm(1000, mean=2) ) data %>% ggplot( aes(x) ) + geom_density( aes(x = x, y = ..density..), binwidth = diff(range(data$x))/30, fill="#69b3a2" ) + geom_label( aes(x=4.5, y=0.25, label="variable1"), color="#69b3a2") + geom_density( aes(x = y, y = -..density..), binwidth = diff(range(data$x))/30, fill= "#404080") + geom_label( aes(x=4.5, y=-0.25, label="variable2"), color="#404080") + theme_ipsum() + xlab("value of x") ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-bacon" role="presentation" aria-label="bacon icon"></i> Densidad ### Densidad múltiple .pull-left[ ```r # Libraries library(ggplot2) library(hrbrthemes) library(dplyr) library(tidyr) library(viridis) # The diamonds dataset is natively available with R. # Without transparency (left) p1 <- ggplot(data=diamonds, aes(x=price, group=cut, fill=cut)) + geom_density(adjust=1.5) + theme_ipsum() p1 ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-bacon" role="presentation" aria-label="bacon icon"></i> Densidad ### Densidad múltiple apilada Otra solución es apilar los grupos. Esto permite ver qué grupo es el más frecuente para un valor dado, pero dificulta la comprensión de la distribución de un grupo que no se encuentra en la parte inferior del gráfico. .pull-left[ ```r # Stacked density plot: p <- ggplot(data=diamonds, aes(x=price, group=cut, fill=cut)) + geom_density(adjust=1.5, position="fill") + theme_ipsum() p ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-circle" role="presentation" aria-label="circle icon"></i> Gráfico de puntos Otra alternativa al histograma es el gráfico de puntos. Nuevamente, la variable cuantitativa se divide en contenedores, pero en lugar de barras de resumen, cada observación está representada por un punto. De forma predeterminada, el ancho de un punto corresponde al ancho del contenedor y los puntos se apilan, y cada punto representa una observación. Esto funciona mejor cuando el número de observaciones es pequeño .pull-left[ ```r # plot the age distribution using a dotplot ggplot(Marriage, aes(x = age)) + geom_dotplot() + labs(title = "Participants by age", y = "Proportion", x = "Age") ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-circle" role="presentation" aria-label="circle icon"></i> Gráfico de puntos .pull-left[ <br> Las opciones `fill` y `color` se pueden utilizar para especificar el relleno y el color del borde de cada punto respectivamente. ---- ```r # Plot ages as a dot plot using # gold dots with black borders ggplot(Marriage, aes(x = age)) + geom_dotplot(fill = "gold", color = "black") + labs(title = "Participants by age", y = "Proportion", x = "Age") ``` ---- Hay muchas otras opciones consultar la ayuda de [dotplot](https://ggplot2.tidyverse.org/reference/geom_dotplot.html) ] .pull-right[ <!-- --> ] --- # <i class="fa fa-chart-bar" role="presentation" aria-label="chart-bar icon"></i> Diagrama de barras El conjunto de datos de matrimonio contiene los registros de matrimonio de 98 personas en el condado de Mobile, Alabama. A continuación, se utiliza un gráfico de barras para mostrar la distribución de los participantes de la boda por raza. .pull-left[ <br> ---- ```r library(ggplot2) data(Marriage, package = "mosaicData") # plot the distribution of race ggplot(Marriage, aes(x = race)) + geom_bar() ``` ---- <br> La mayoría de los participantes son blancos, seguidos por negros, con muy pocos hispanos o indios americanos. ] .pull-right[ <!-- --> ] --- # <i class="fa fa-chart-bar" role="presentation" aria-label="chart-bar icon"></i> Diagrama de barras .pull-left[ Puede modificar el relleno de la barra y los colores del borde, las etiquetas de trazado y el título agregando opciones a la función `geom_bar`. <br> ---- ```r # plot the distribution of race with modified colors and labels ggplot(Marriage, aes(x = race)) + geom_bar(fill = "cornflowerblue", color="black") + labs(x = "Race", y = "Frequency", title = "Participants by race") ``` ---- ] .pull-right[ <!-- --> ] --- # <i class="fa fa-chart-bar" role="presentation" aria-label="chart-bar icon"></i> Diagrama de barras .pull-left[ **Las barras pueden representar porcentajes en lugar de recuentos.** Para los gráficos de barras, el código `aes(x=race)` es en realidad un atajo para `aes(x = race, y = ..count..)` , donde **..count..** es una variable especial que representa la frecuencia dentro de cada categoría. Puede usar esto para calcular porcentajes, especificando la variable **Y** explícitamente. ---- ```r # plot the distribution as percentages ggplot(Marriage, aes(x = race, y = ..count.. / sum(..count..))) + geom_bar() + labs(x = "Race", y = "Percent", title = "Participants by race") + scale_y_continuous(labels = scales::percent) ``` ---- > En el código anterior, el paquete `scales` se usa para agregar **%** a las etiquetas del eje y. ] .pull-right[ <!-- --> ] --- # <i class="fa fa-chart-bar" role="presentation" aria-label="chart-bar icon"></i> Diagrama de barras ### Orden de categorías .pull-left[ La función `reorder` se usa para ordenar las categorías por frecuencia. La opción `stat="identity"` le dice a la función de trazado que no calcule los recuentos, porque se suministran directamente. ---- ```r library(dplyr) plotdata <- Marriage %>% count(race) ``` ---- |race | n| |:---------------|--:| |American Indian | 1| |Black | 22| |Hispanic | 1| |White | 74| ] .pull-right[ <!-- --> Las barras del gráfico están ordenadas en orden ascendente. Use `reorder(race, -n)`para ordenar en orden descendente. ] --- # <i class="fa fa-chart-bar" role="presentation" aria-label="chart-bar icon"></i> Diagrama de barras ### Etiquetado de barras .pull-left[ ---- ```r # plot the bars with numeric labels ggplot(plotdata, aes(x = race, y = n)) + geom_bar(stat = "identity") + geom_text(aes(label = n), vjust=-0.5) + labs(x = "Race", y = "Frequency", title = "Participants by race") ``` ---- > Aquí `geom_text` agrega las etiquetas y `vjust` controla la justificación vertical. ] .pull-right[ <!-- --> ] --- # <i class="fa fa-chart-bar" role="presentation" aria-label="chart-bar icon"></i> Diagrama de barras ### Etiquetado de barras .pull-left[ ---- ```r library(dplyr) library(scales) plotdata <- Marriage %>% count(race) %>% mutate(pct = n / sum(n), pctlabel = paste0(round(pct*100), "%")) # plot the bars as percentages, # in decending order with bar labels ggplot(plotdata, aes(x = reorder(race, -pct), y = pct)) + geom_bar(stat = "identity", fill = "indianred3", color = "black") + geom_text(aes(label = pctlabel), vjust = -0.25) + scale_y_continuous(labels = percent) + labs(x = "Race", y = "Percent", title = "Participants by race") ``` ---- ] .pull-right[ <!-- --> ] --- # <i class="fa fa-chart-bar" role="presentation" aria-label="chart-bar icon"></i> Diagrama de barras ### Etiquetas superpuestas .pull-left[ Las etiquetas de categoría pueden superponerse si (1) hay muchas categorías o (2) las etiquetas son largas. Considere la distribución de funcionarios matrimoniales. ---- ```r # basic bar chart with overlapping labels ggplot(Marriage, aes(x = officialTitle)) + geom_bar() + labs(x = "Officiate", y = "Frequency", title = "Marriages by officiate") ``` ---- ] .pull-right[ <!-- --> ] --- # <i class="fa fa-chart-bar" role="presentation" aria-label="chart-bar icon"></i> Diagrama de barras ### Barras horizontales .pull-left[ La función `coord_flip()` le permite invertir los ejes *X* y *Y* ---- ```r # horizontal bar chart ggplot(Marriage, aes(x = officialTitle)) + geom_bar() + labs(x = "", y = "Frequency", title = "Marriages by officiate") + coord_flip() ``` ---- ] .pull-right[ <!-- --> ] --- # <i class="fa fa-chart-bar" role="presentation" aria-label="chart-bar icon"></i> Diagrama de barras ### Etiquetas a 45° .pull-left[ Alternativamente puede rotar los ejes ---- ```r ggplot(Marriage, aes(x = officialTitle)) + geom_bar() + labs(x = "", y = "Frequency", title = "Marriages by officiate") + theme(axis.text.x = element_text(angle = 45, hjust = 1)) ``` ---- ] .pull-right[ <!-- --> ] --- # <i class="fa fa-chart-pie" role="presentation" aria-label="chart-pie icon"></i> Gráfico cirular o pie Los gráficos circulares son controvertidos en las estadísticas. <br> * Si su objetivo es comparar la frecuencia de las categorías, le irá mejor con los gráficos de barras (los humanos son mejores para juzgar la longitud de las barras que el volumen de las porciones circulares). * Si su objetivo es comparar cada categoría con el total (por ejemplo, qué parte de los participantes son hispanos en comparación con todos los participantes) y el número de categorías es pequeño, entonces los gráficos circulares pueden funcionar para usted. Se necesita un poco más de código para hacer un gráfico circular atractivo en R. .pull-left[ ---- .scroll-box-14[ ```r # create data plotdata <- Marriage %>% count(race) %>% arrange(desc(race)) %>% mutate(prop = round(n * 100 / sum(n), 1), lab.ypos = cumsum(prop) - 0.5 *prop) # create plot ggplot(plotdata, aes(x = "", y = prop, fill = race)) + geom_bar(width = 1, stat = "identity", color = "black") + coord_polar("y", start = 0, direction = -1) + theme_void() ``` ] ---- ] .pull-right[ <!-- --> ] --- # <i class="fa fa-chart-pie" role="presentation" aria-label="chart-pie icon"></i> Gráfico cirular o pie ### Agregar etiquetas al pie El gráfico circular facilita la comparación de cada sector con el conjunto. Por ejemplo, se considera que `Black` representa aproximadamente una cuarta parte del total de participantes. .pull-left[ ---- .scroll-box-16[ ```r # create a pie chart with slice labels plotdata <- Marriage %>% count(race) %>% arrange(desc(race)) %>% mutate(prop = round(n*100/sum(n), 1), lab.ypos = cumsum(prop) - 0.5*prop) plotdata$label <- paste0(plotdata$race, "\n", round(plotdata$prop), "%") # create plot ggplot(plotdata, aes(x = "", y = prop, fill = race)) + geom_bar(width = 1, stat = "identity", color = "black") + geom_text(aes(y = lab.ypos, label = label), color = "black") + coord_polar("y", start = 0, direction = -1) + theme_void() + theme(legend.position = "FALSE") + labs(title = "Participants by race") ``` ] ---- ] .pull-right[ <!-- --> ] --- # <i class="fa fa-box" role="presentation" aria-label="box icon"></i> Mapa de árbol Una alternativa a un gráfico circular es un mapa de árbol. A diferencia de los gráficos circulares, puede manejar variables categóricas que tienen muchos niveles. .pull-left[ ---- ```r library(treemapify) # create a treemap of marriage officials plotdata <- Marriage %>% count(officialTitle) ggplot(plotdata, aes(fill = officialTitle, area = n)) + geom_treemap() + labs(title = "Marriages by officiate") ``` ---- ] .pull-right[ <!-- --> ] --- # <i class="fa fa-box" role="presentation" aria-label="box icon"></i> Mapa de árbol ### Agregar etiquetas .pull-left[ ---- ```r # create a treemap with tile labels ggplot(plotdata, aes(fill = officialTitle, area = n, label = officialTitle)) + geom_treemap() + geom_treemap_text(colour = "white", place = "centre") + labs(title = "Marriages by officiate") + theme(legend.position = "none") ``` ---- ] .pull-right[ <!-- --> ] --- name: Bivariados class: inverse, center, middle # <i class="fa fa-list-ol" role="presentation" aria-label="list-ol icon"></i> # Gráficos Bivariados ---- .right[ .bottom[ #### [<i class="fa fa-bell" role="presentation" aria-label="bell icon"></i>](#menu) ] ] --- # <i class="fa fa-chart-bar" role="presentation" aria-label="chart-bar icon"></i> Barras apiladas Al trazar la relación entre dos variables categóricas, normalmente se utilizan gráficos de barras apiladas, agrupadas o segmentadas. .pull-left[ Tracemos la relación entre la clase de automóvil y el tipo de tracción (rueda delantera, trasera o tracción en las 4 ruedas) para los automóviles en el dataset (mpg). ---- ```r library(ggplot2) # stacked bar chart ggplot(mpg, aes(x = class, fill = drv)) + geom_bar(position = "stack") ``` ---- El vehículo más común es el SUV. Todos los autos de 2 plazas tienen tracción trasera, mientras que la mayoría, pero no todos los SUV, tienen tracción en las 4 ruedas. ] .pull-right[ <!-- --> `Stacked es el valor por default, por lo que la última línea también podría haberse escrito como geom_bar().` ] --- # <i class="fa fa-chart-bar" role="presentation" aria-label="chart-bar icon"></i> Barras agrupadas Los gráficos de barras agrupadas colocan las barras para la segunda variable categórica una al lado de la otra. Para crear un diagrama de barras agrupadas, use la opción `position = "dodge"` .pull-left[ ---- ```r library(ggplot2) # grouped bar plot ggplot(mpg, aes(x = class, fill = drv)) + geom_bar(position = "dodge") ``` ---- > Tenga en cuenta que todas las minivans tienen tracción delantera. De forma predeterminada, las barras de recuento cero se eliminan y las barras restantes se hacen más anchas. Puede que este no sea el comportamiento que desea. Puede modificar esto usando `position = position_dodge(preserve = "single")`. ] .pull-right[ <!-- --> ] --- # <i class="fa fa-chart-bar" role="presentation" aria-label="chart-bar icon"></i> Barras segmentadas Un gráfico de barras segmentadas es un gráfico de barras apiladas donde cada barra representa el 100 por ciento. Puede crear un gráfico de barras segmentado usando `position = "fill"` .pull-left[ ---- ```r library(ggplot2) # bar plot, with each bar representing 100% ggplot(mpg, aes(x = class, fill = drv)) + geom_bar(position = "fill") + labs(y = "Proportion") ``` ---- > Este tipo de gráfico es particularmente útil si el objetivo es comparar el porcentaje de una categoría en una variable en cada nivel de otra variable. Por ejemplo, la proporción de automóviles con tracción delantera aumenta a medida que se pasa de un modelo compacto a un tamaño mediano a una minivan. ] .pull-right[ <!-- --> ] --- # <i class="fa fa-chart-bar" role="presentation" aria-label="chart-bar icon"></i> Barras segmentadas Un gráfico de barras segmentadas es un gráfico de barras apiladas donde cada barra representa el 100 por ciento. Puede crear un gráfico de barras segmentado usando `position = "fill"` .pull-left[ ---- ```r library(ggplot2) # bar plot, with each bar representing 100% ggplot(mpg, aes(x = class, fill = drv)) + geom_bar(position = "fill") + labs(y = "Proportion") ``` ---- > Este tipo de gráfico es particularmente útil si el objetivo es comparar el porcentaje de una categoría en una variable en cada nivel de otra variable. Por ejemplo, la proporción de automóviles con tracción delantera aumenta a medida que se pasa de un modelo compacto a un tamaño mediano a una minivan. ] .pull-right[ <!-- --> ] --- # <i class="fa fa-chart-bar" role="presentation" aria-label="chart-bar icon"></i> Barras segmentadas (Mejoras gráficas) Puede utilizar opciones adicionales para mejorar el color y el etiquetado. * `factor` modifica el orden de las categorías para la variable de clase y tanto el orden como las etiquetas para la variable de unidad. * `scale_y_continuous` modifica las etiquetas de las marcas del eje *Y*. * `labs` proporciona un título y cambio en las etiquetas de los ejes *X* y *Y*, además de la leyenda. * `scale_fill_brewer` cambia el esquema de color de relleno. * `theme_minimal` elimina el fondo gris y cambia el color de la cuadrícula. .pull-left[ ---- .scroll-box-14[ ```r library(ggplot2) # bar plot, with each bar representing 100%, # reordered bars, and better labels and colors library(scales) ggplot(mpg, aes(x = factor(class, levels = c("2seater", "subcompact", "compact", "midsize", "minivan", "suv", "pickup")), fill = factor(drv, levels = c("f", "r", "4"), labels = c("front-wheel", "rear-wheel", "4-wheel")))) + geom_bar(position = "fill") + scale_y_continuous(breaks = seq(0, 1, .2), label = percent) + scale_fill_brewer(palette = "Set2") + labs(y = "Percent", fill = "Drive Train", x = "Class", title = "Automobile Drive by Class") + theme_minimal() ``` ] ---- ] .pull-right[ <!-- --> ] --- # <i class="fa fa-chart-bar" role="presentation" aria-label="chart-bar icon"></i> Barras segmentadas (Mejoras gráficas) > Agregando etiquetas .pull-left[ ---- .scroll-box-14[ ```r # create a summary dataset library(dplyr) plotdata <- mpg %>% group_by(class, drv) %>% summarize(n = n()) %>% mutate(pct = n/sum(n), lbl = scales::percent(pct)) plotdata # create segmented bar chart # adding labels to each segment ggplot(plotdata, aes(x = factor(class, levels = c("2seater", "subcompact", "compact", "midsize", "minivan", "suv", "pickup")), y = pct, fill = factor(drv, levels = c("f", "r", "4"), labels = c("front-wheel", "rear-wheel", "4-wheel")))) + geom_bar(stat = "identity", position = "fill") + scale_y_continuous(breaks = seq(0, 1, .2), label = percent) + geom_text(aes(label = lbl), size = 3, position = position_stack(vjust = 0.5)) + scale_fill_brewer(palette = "Set2") + labs(y = "Percent", fill = "Drive Train", x = "Class", title = "Automobile Drive by Class") + theme_minimal() ``` ] ---- ] .pull-right[ <!-- --> ] --- # <i class="fa fa-chart-bar" role="presentation" aria-label="chart-bar icon"></i> Barras: Resumen de Media > También puede utilizar gráficos de barras para mostrar otros estadísticos de resumen (por ejemplo, medias o medianas) en una variable cuantitativa para cada nivel de una variable categórica. > Por ejemplo, el siguiente gráfico muestra el salario medio de una muestra de profesores universitarios por rango académico. .pull-left[ ---- .scroll-box-14[ ```r data(Salaries, package="carData") # calculate mean salary for each rank library(dplyr) plotdata <- Salaries %>% group_by(rank) %>% summarize(mean_salary = mean(salary)) # plot mean salaries in a more attractive fashion library(scales) ggplot(plotdata, aes(x = factor(rank, labels = c("Assistant\nProfessor", "Associate\nProfessor", "Full\nProfessor")), y = mean_salary)) + geom_bar(stat = "identity", fill = "cornflowerblue") + geom_text(aes(label = dollar(mean_salary)), vjust = -0.25) + scale_y_continuous(breaks = seq(0, 130000, 20000), label = dollar) + labs(title = "Mean Salary by Rank", subtitle = "9-month academic salary for 2008-2009", x = "", y = "") ``` ] ---- ] .pull-right[ <!-- --> ] --- # <i class="fa fa-spinner" role="presentation" aria-label="spinner icon"></i> Diagramas de dispersión La visualización más simple de dos variables cuantitativas es un diagrama de dispersión, con cada variable representada en un eje. Por ejemplo, al utilizar el conjunto de datos `Salaries`, podemos graficar la experiencia *(yrs.since.phd)* frente al salario académico *(salary)* de los profesores universitarios. .pull-left[ ---- ```r library(ggplot2) data(Salaries, package="carData") # simple scatterplot ggplot(Salaries, aes(x = yrs.since.phd, y = salary)) + geom_point() ``` ---- Las opciones se pueden utilizar para cambiar el `geom_point()`. * `color` - color de punto * `size` - tamaño de punto * `shape` - forma de punto * `alpha` - transparencia de punto (va de 0 a 1) (0: transparente, 1: opaco) * `scale_x_continuous` y `scale_y_continuous` escala de los ejes. ] .pull-right[ <!-- --> ] --- # <i class="fa fa-spinner" role="presentation" aria-label="spinner icon"></i> Diagramas de dispersión ### Mejoras visuales .pull-left[ ---- ```r # enhanced scatter plot ggplot(Salaries, aes(x = yrs.since.phd, y = salary)) + geom_point(color="cornflowerblue", size = 2, alpha=.8) + scale_y_continuous(label = scales::dollar, limits = c(50000, 250000)) + scale_x_continuous(breaks = seq(0, 60, 10), limits=c(0, 60)) + labs(x = "Years Since PhD", y = "", title = "Experience vs. Salary", subtitle = "9-month salary for 2008-2009") ``` ---- ] .pull-right[ <!-- --> ] --- # <i class="fa fa-spinner" role="presentation" aria-label="spinner icon"></i> Diagramas de dispersión ### Linea de ajuste .pull-left[ A menudo es útil resumir la relación que se muestra en el diagrama de dispersión, utilizando una línea de mejor ajuste. Se admiten muchos tipos de líneas, incluidas las lineales, polinomiales y no paramétricas (loess). De forma predeterminada, se muestran los límites de confianza del 95% para estas líneas. ---- ```r # scatterplot with linear fit line ggplot(Salaries, aes(x = yrs.since.phd, y = salary)) + geom_point(color= "steelblue") + geom_smooth(method = "lm") ``` ---- ] .pull-right[ <!-- --> ] --- # <i class="fa fa-spinner" role="presentation" aria-label="spinner icon"></i> Diagramas de dispersión ### Smooth .pull-left[ Una línea de ajuste no paramétrica suavizada a menudo puede proporcionar una buena imagen de la relación. El valor predeterminado en ggplot2 es una suavización loess. ---- ```r # scatterplot with loess smoothed line ggplot(Salaries, aes(x = yrs.since.phd, y = salary)) + geom_point(color= "steelblue") + geom_smooth(color = "tomato") ``` ---- Puede suprimir las bandas de confianza al incluir la opción `se = FALSE` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-spinner" role="presentation" aria-label="spinner icon"></i> Diagramas de dispersión ### Smooth .pull-left[ ---- ```r # scatterplot with loess smoothed line # and better labeling and color ggplot(Salaries, aes(x = yrs.since.phd, y = salary)) + geom_point(color="cornflowerblue", size = 2, alpha = .6) + geom_smooth(size = 1.5, color = "darkgrey") + scale_y_continuous(label = scales::dollar, limits = c(50000, 250000)) + scale_x_continuous(breaks = seq(0, 60, 10), limits = c(0, 60)) + labs(x = "Years Since PhD", y = "", title = "Experience vs. Salary", subtitle = "9-month salary for 2008-2009") + theme_minimal() ``` ---- ] .pull-right[ <!-- --> ] --- # <i class="fa fa-people-carry" role="presentation" aria-label="people-carry icon"></i> Boxplot Un diagrama de caja ofrece un buen resumen de una o más variables numéricas. Un diagrama de caja se compone de varios elementos: .pull-left[ * La línea que divide el cuadro en 2 partes representa la mediana de los datos. Si la mediana es 10, significa que hay el mismo número de puntos de datos por debajo y por encima de 10. * Los extremos del cuadro muestran los cuartiles superior (Q3) e inferior (Q1) . Si el tercer cuartil es 15, significa que el 75% de las observaciones son inferiores a 15. * La diferencia entre los cuartiles 1 y 3 se llama rango intercuartil (IQR). * La línea extrema muestra Q3 + 1.5xIQR a Q1-1.5xIQR (el valor más alto y más bajo excluyendo los valores atípicos). * Los puntos (u otros marcadores) más allá de la línea extrema muestran valores atípicos potenciales. ] .pull-right[ ### Errores comunes > * Boxplot oculta el tamaño de la muestra de cada grupo, muéstrelo con una anotación o el ancho del cuadro. <br> > * Boxplot oculta la distribución subyacente . Use jitter si hay pocos puntos de datos o use un violín con datos más grandes. <br> > * Ordenar su diagrama de caja por mediana puede hacerlo más revelador. ] --- # <i class="fa fa-people-carry" role="presentation" aria-label="people-carry icon"></i> Boxplot ### Diagrama de caja o Boxplot <img src="img/img2.JPG" width="89%"/> ---- .right[ Fuente: [Denise Coleman](https://www.leansigmacorporation.com/box-plot-with-minitab/) ] --- # <i class="fa fa-people-carry" role="presentation" aria-label="people-carry icon"></i> Boxplot .pull-left[ * `Un diagrama de caja puede resumir la distribución de una variable numérica para varios grupos.` <br><br> * `El problema es que resumir también significa perder información y eso puede ser una trampa.` <br><br> * `Si consideramos el diagrama de caja a continuación, es fácil concluir que el grupo Ctiene un valor más alto que los demás.` <br><br> * `Sin embargo, no podemos ver la distribución subyacente de puntos en cada grupo o su número de observaciones.` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-people-carry" role="presentation" aria-label="people-carry icon"></i> Boxplot .pull-left[ > Los diagramas de caja lado a lado son muy útiles para comparar grupos (es decir, los niveles de una variable categórica) en una variable numérica. ---- ```r # plot the distribution of salaries by rank using boxplots ggplot(Salaries, aes(x = rank, y = salary)) + geom_boxplot() + labs(title = "Salary distribution by rank") ``` ---- ] .pull-right[ <!-- --> ] --- # <i class="fa fa-people-carry" role="presentation" aria-label="people-carry icon"></i> Boxplot .pull-left[ ```r # Libraries library(tidyverse) library(hrbrthemes) library(viridis) library(plotly) # create a dataset data <- data.frame( name=c( rep("A",500), rep("B",500), rep("B",500), rep("C",20), rep('D', 100) ), value=c( rnorm(500, 10, 5), rnorm(500, 13, 1), rnorm(500, 18, 1), rnorm(20, 25, 4), rnorm(100, 12, 1) ) ) # Plot data %>% ggplot( aes(x=name, y=value, fill=name)) + geom_boxplot() + scale_fill_viridis(discrete = TRUE) + theme_ipsum() + theme( legend.position="none", plot.title = element_text(size=11) ) + ggtitle("A somewhat misleading boxplot") + xlab("") ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-people-carry" role="presentation" aria-label="people-carry icon"></i> Boxplot Si la cantidad de datos con la que está trabajando no es demasiado grande, agregar `jitter` en la parte superior de su diagrama de caja puede hacer que el gráfico sea más revelador. .pull-left[ >Aquí aparecen claramente algunos patrones nuevos. ---- > El grupo C tiene un tamaño de muestra pequeño en comparación con los otros grupos. ---- > Definitivamente, esto es algo que debe averiguar antes de decir que el grupo C tiene un valor más alto que los demás. ---- >Además, parece que el grupo B tiene un bimodal distribution: los puntos se distribuyen en 2 grupos: alrededor de y = 18 e y = 13. ] .pull-right[ <!-- --> ] --- # <i class="fa fa-people-carry" role="presentation" aria-label="people-carry icon"></i> Boxplot .pull-left[ ```r # Plot data %>% ggplot( aes(x=name, y=value, fill=name)) + geom_boxplot() + scale_fill_viridis(discrete = TRUE) + geom_jitter(color="grey", size=0.7, alpha=0.5) + theme_ipsum() + theme( legend.position="none", plot.title = element_text(size=11) ) + ggtitle("A boxplot with jitter") + xlab("") ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-people-carry" role="presentation" aria-label="people-carry icon"></i> Boxplot Si tiene un tamaño de muestra grande, el uso `jitter` ya no es una opción, ya que los puntos se superpondrán, haciendo que la figura no se pueda interpretar. Una alternativa es el diagrama de violín , que describe la distribución de los datos para cada grupo: .pull-left[ > Aquí está muy claro que los grupos tienen distribuciones diferentes. La distribución bimodal del grupo B se vuelve obvia. ---- > Los diagramas de violín son una forma poderosa de mostrar información; probablemente estén infrautilizados en comparación con los diagramas de caja.` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-people-carry" role="presentation" aria-label="people-carry icon"></i> Boxplot .pull-left[ ```r # sample size sample_size = data %>% group_by(name) %>% summarize(num=n()) # Plot data %>% left_join(sample_size) %>% mutate(myaxis = paste0(name, "\n", "n=", num)) %>% ggplot( aes(x=myaxis, y=value, fill=name)) + geom_violin(width=1.4) + geom_boxplot(width=0.1, color="grey", alpha=0.2) + scale_fill_viridis(discrete = TRUE) + theme_ipsum() + theme( legend.position="none", plot.title = element_text(size=11) ) + ggtitle("A boxplot with jitter") + xlab("") ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-people-carry" role="presentation" aria-label="people-carry icon"></i> Boxplot **Reordenar los grupos en un ggplot2 gráfico puede resultar complicado.** Esto se debe al hecho de que ggplot2 tiene en cuenta el orden de los factorniveles, no el orden que observa en su marco de datos. Puede ordenar su marco de datos de entrada con sort()o arrange(), nunca tendrá ningún impacto en su salida de ggplot2. .pull-left[ ```r # Library library(ggplot2) library(dplyr) library(forcats) # Using median mpg %>% mutate(class = fct_reorder(class, hwy, .fun='median')) %>% ggplot( aes(x=reorder(class, hwy), y=hwy, fill=class)) + geom_boxplot() + xlab("class") + theme(legend.position="none") + xlab("") ``` `La biblioteca Forecats es una biblioteca de tidyverse especialmente diseñada para manejar factores en R.` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-people-carry" role="presentation" aria-label="people-carry icon"></i> Boxplot ### Control de color .pull-left[ ```r # library library(ggplot2) # The mtcars dataset is natively available in R #head(mpg) #Set a unique color with fill, colour, and alpha ggplot(mpg, aes(x=class, y=hwy)) + geom_boxplot(color="red", fill="orange", alpha=0.2) # Set a different color for each group ggplot(mpg, aes(x=class, y=hwy, fill=class)) + geom_boxplot(alpha=0.3) + theme(legend.position="none") # Palette ggplot(mpg, aes(x=class, y=hwy, fill=class)) + geom_boxplot(alpha=0.3) + theme(legend.position="none") + scale_fill_brewer(palette="Dark2") ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-people-carry" role="presentation" aria-label="people-carry icon"></i> Boxplot ### Destacar un grupo `Primero cree una nueva columna mutate donde almacena la información binaria: resaltar o no. Luego solo proporcione esta columna al argumento fill y eventualmente personalice la apariencia del grupo resaltado con scale_fill_manual y scale_alpha_manual.` .pull-left[ .scroll-box-16[ ```r library(ggplot2) library(dplyr) library(hrbrthemes) # Work with the natively available mpg dataset mpg %>% # Add a column called 'type': do we want to highlight the group or not? mutate( type=ifelse(class=="subcompact","Highlighted","Normal")) %>% # Build the boxplot. In the 'fill' argument, give this column ggplot( aes(x=class, y=hwy, fill=type, alpha=type)) + geom_boxplot() + scale_fill_manual(values=c("#69b3a2", "grey")) + scale_alpha_manual(values=c(1,0.1)) + theme_ipsum() + theme(legend.position = "none") + xlab("") ``` ] ] .pull-right[ <!-- --> ] --- # <i class="fa fa-people-carry" role="presentation" aria-label="people-carry icon"></i> Boxplot ### Boxplot agrupado `Tenga en cuenta que se debe llamar al grupo en el argumento X de ggplot2. El subgrupo se llama en el argumento fill.` .pull-left[ ```r # library library(ggplot2) # create a data frame variety=rep(LETTERS[1:7], each=40) treatment=rep(c("high","low"),each=20) note=seq(1:280)+sample(1:150, 280, replace=T) data=data.frame(variety, treatment , note) # grouped boxplot ggplot(data, aes(x=variety, y=note, fill=treatment)) + geom_boxplot() ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-people-carry" role="presentation" aria-label="people-carry icon"></i> Boxplot ### Boxplot agrupado en paneles .pull-left[ ```r # library library(ggplot2) # create a data frame variety=rep(LETTERS[1:7], each=40) treatment=rep(c("high","low"),each=20) note=seq(1:280)+sample(1:150, 280, replace=T) data=data.frame(variety, treatment , note) # One box per treatment ggplot(data, aes(x=variety, y=note, fill=treatment)) + geom_boxplot() + facet_wrap(~treatment) ``` **Importante la función facet_wrap()** ] .pull-right[ <!-- --> ] --- # <i class="fa fa-people-carry" role="presentation" aria-label="people-carry icon"></i> Boxplot ### Boxplot agrupado en paneles .pull-left[ ```r # library library(ggplot2) # create a data frame variety=rep(LETTERS[1:7], each=40) treatment=rep(c("high","low"),each=20) note=seq(1:280)+sample(1:150, 280, replace=T) data=data.frame(variety, treatment , note) # one box per variety p2 <- ggplot(data, aes(x=variety, y=note, fill=treatment)) + geom_boxplot() + facet_wrap(~variety, scale="free") ``` **Importante la función facet_wrap()** ] .pull-right[ <!-- --> ] --- # <i class="fa fa-people-carry" role="presentation" aria-label="people-carry icon"></i> Boxplot ### Boxplot para variable continua .pull-left[ .scroll-box-10[ ```r # library library(ggplot2) library(dplyr) library(hrbrthemes) # Start with the diamonds dataset, natively available in R: p <- diamonds %>% # Add a new column called 'bin': cut the initial 'carat' in bins mutate( bin=cut_width(carat, width=0.5, boundary=0) ) %>% # plot ggplot( aes(x=bin, y=price) ) + geom_boxplot(fill="#69b3a2") + theme_ipsum() + xlab("Carat") ``` ] Estudiar la relación entre 2 variables numéricas. Es posible cortar en diferentes contenedores y usar los grupos creados para construir un diagrama de caja. <br> La variable numérica llamada `carat`del set diamonds se corta en contenedores de 0.5 gracias a la función `cut_width.` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-route" role="presentation" aria-label="route icon"></i> Ridgeline Un diagrama de línea de cresta (también llamado diagrama de control) muestra la distribución de una variable cuantitativa para varios grupos. Son similares a las gráficas de densidad de kernel con facetas verticales, pero ocupan menos espacio. Los gráficos de Ridgeline se crean con el paquete `ggridges`. .pull-left[ Utilizando el conjunto de datos de economía de combustible, tracemos la distribución de las millas por galón de conducción en la ciudad por clase de automóvil. .scroll-box-10[ ```r # create ridgeline graph library(ggplot2) library(ggridges) ggplot(mpg, aes(x = cty, y = class, fill = class)) + geom_density_ridges() + theme_ridges() + labs("Highway mileage by auto class") + theme(legend.position = "none") ``` ] Como era de esperar, las camionetas pickup tienen el kilometraje más bajo, mientras que los subcompactos y los autos compactos tienden a obtener calificaciones. ] .pull-right[ <!-- --> ] --- # <i class="fa fa-trailer" role="presentation" aria-label="trailer icon"></i> SEM plots (Gráficos de media) Un método popular para comparar grupos en una variable numérica es la gráfica media con barras de error. Las barras de error pueden representar desviaciones estándar, error estándar de la media o intervalos de confianza. .pull-left[ ---- .scroll-box-10[ ```r # calculate means, standard deviations, # standard errors, and 95% confidence # intervals by rank library(dplyr) plotdata <- Salaries %>% group_by(rank) %>% summarize(n = n(), mean = mean(salary), sd = sd(salary), se = sd / sqrt(n), ci = qt(0.975, df = n - 1) * sd / sqrt(n)) plotdata %>% knitr::kable() # Create plot ggplot(plotdata, aes(x = rank, y = mean, group = 1)) + geom_point(size = 3) + geom_line() + geom_errorbar(aes(ymin = mean - se, ymax = mean + se), width = .1) ``` ] ---- <div id="htmlwidget-6f0ad5742ebb60dd8194" style="width:100%;height:auto;" class="datatables html-widget"></div> <script type="application/json" data-for="htmlwidget-6f0ad5742ebb60dd8194">{"x":{"filter":"none","extensions":["FixedColumns"],"data":[["1","2","3"],["AsstProf","AssocProf","Prof"],[67,64,266],[80775.9850746269,93876.4375,126772.109022556],[8174.1126373977,13831.6998437452,27718.6749989516],[998.626799016729,1728.96248046815,1699.54100802556],[1993.82273472904,3455.05582121672,3346.3219431289]],"container":"<table class=\"display\">\n <thead>\n <tr>\n <th> <\/th>\n <th>rank<\/th>\n <th>n<\/th>\n <th>mean<\/th>\n <th>sd<\/th>\n <th>se<\/th>\n <th>ci<\/th>\n <\/tr>\n <\/thead>\n<\/table>","options":{"dom":"t","scrollX":true,"scrollCollapse":true,"columnDefs":[{"className":"dt-right","targets":[2,3,4,5,6]},{"orderable":false,"targets":0}],"order":[],"autoWidth":false,"orderClasses":false}},"evals":[],"jsHooks":[]}</script> ] .pull-right[ <!-- --> ] --- # <i class="fa fa-trailer" role="presentation" aria-label="trailer icon"></i> SEM plots (Gráficos de media) ### Comparación de grupos .pull-left[ Podemos utilizar la misma técnica para comparar el salario según el rango y el sexo. (Técnicamente, esto no es bivariado ya que estamos trazando rango, sexo y salario, pero parece encajar aquí) .scroll-box-14[ ```r # calculate means, standard deviations, # standard errors, and 95% confidence # intervals by rank library(dplyr) plotdata <- Salaries %>% group_by(rank, sex) %>% summarize(n = n(), mean = mean(salary), sd = sd(salary), se = sd/sqrt(n)) pd <- position_dodge(0.2) ggplot(plotdata, aes(x = factor(rank, labels = c("Assistant\nProfessor", "Associate\nProfessor", "Full\nProfessor")), y = mean, group=sex, color=sex)) + geom_point(position=pd, size = 3) + geom_line(position = pd, size = 1) + geom_errorbar(aes(ymin = mean - se, ymax = mean + se), width = .1, position = pd, size = 1) + scale_y_continuous(label = scales::dollar) + scale_color_brewer(palette="Set1") + theme_minimal() + labs(title = "Mean salary by rank and sex", subtitle = "(mean +/- standard error)", x = "", y = "", color = "Gender") ``` ] ] .pull-right[ <!-- --> ] --- # <i class="fab fa-blackberry" role="presentation" aria-label="blackberry icon"></i> Strip plots La relación entre una variable de agrupación y una variable numérica se puede mostrar con un diagrama de dispersión. Por ejemplo: .pull-left[ .scroll-box-14[ ```r # plot the distribution of salaries # by rank using jittering ggplot(Salaries, aes(y = rank, x = salary)) + geom_jitter() + labs(title = "Salary distribution by rank") ``` ] ] .pull-right[ <!-- --> ] --- # <i class="fab fa-blackberry" role="presentation" aria-label="blackberry icon"></i> Strip plots La relación entre una variable de agrupación y una variable numérica se puede mostrar con un diagrama de dispersión. Por ejemplo: .pull-left[ .scroll-box-18[ ```r # plot the distribution of salaries # by rank using jittering library(scales) ggplot(Salaries, aes(y = factor(rank, labels = c("Assistant\nProfessor", "Associate\nProfessor", "Full\nProfessor")), x = salary, color = rank)) + geom_jitter(alpha = 0.7, size = 1.5) + scale_x_continuous(label = dollar) + labs(title = "Academic Salary by Rank", subtitle = "9-month salary for 2008-2009", x = "", y = "") + theme_minimal() + theme(legend.position = "none") ``` ] La opción `legend.position = "none"` se usa para suprimir la leyenda (que no es necesaria aquí). ] .pull-right[ <!-- --> ] --- # <i class="fa fa-dice-four" role="presentation" aria-label="dice-four icon"></i> Cleveland Dot Charts Los gráficos de Cleveland son útiles cuando desea comparar una estadística numérica para una gran cantidad de grupos. Por ejemplo, digamos que desea comparar la esperanza de vida de 2007 para un país asiático utilizando el conjunto de datos `gapminder`. .pull-left[ .scroll-box-18[ ```r data(gapminder, package="gapminder") # subset Asian countries in 2007 library(dplyr) plotdata <- gapminder %>% filter(continent == "Asia" & year == 2007) # basic Cleveland plot of life expectancy by country ggplot(plotdata, aes(x= lifeExp, y = country)) + geom_point() ``` ] ] .pull-right[ <!-- --> ] --- # <i class="fa fa-dice-four" role="presentation" aria-label="dice-four icon"></i> Cleveland Dot Charts Las comparaciones suelen ser más fáciles si se ordena el eje `Y`. .pull-left[ .scroll-box-18[ ```r data(gapminder, package="gapminder") # subset Asian countries in 2007 library(dplyr) plotdata <- gapminder %>% filter(continent == "Asia" & year == 2007) # Sorted Cleveland plot ggplot(plotdata, aes(x=lifeExp, y=reorder(country, lifeExp))) + geom_point() ``` ] ] .pull-right[ <!-- --> ] --- # <i class="fa fa-dice-four" role="presentation" aria-label="dice-four icon"></i> Cleveland Dot Charts Finalmente, podemos usar opciones para hacer más atractivo el gráfico. .pull-left[ .scroll-box-18[ ```r data(gapminder, package="gapminder") # subset Asian countries in 2007 library(dplyr) plotdata <- gapminder %>% filter(continent == "Asia" & year == 2007) # Fancy Cleveland plot ggplot(plotdata, aes(x=lifeExp, y=reorder(country, lifeExp))) + geom_point(color="blue", size = 2) + geom_segment(aes(x = 40, xend = lifeExp, y = reorder(country, lifeExp), yend = reorder(country, lifeExp)), color = "lightgrey") + labs (x = "Life Expectancy (years)", y = "", title = "Life Expectancy by Country", subtitle = "GapMinder data for Asia - 2007") + theme_minimal() + theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank()) ``` ] ] .pull-right[ <!-- --> ] --- name: Multi class: inverse, center, middle # <i class="fab fa-buffer" role="presentation" aria-label="buffer icon"></i> # Gráficos Multivariados ---- .right[ .bottom[ #### [<i class="fa fa-bell" role="presentation" aria-label="bell icon"></i>](#menu) ] ] --- # <i class="fab fa-delicious" role="presentation" aria-label="delicious icon"></i> Agrupación En la agrupación, los valores de las dos primeras variables se asignan a la x y Y ejes. Luego, las variables adicionales se asignan a otras características visuales como el color, la forma, el tamaño, el tipo de línea y la transparencia. La agrupación le permite trazar los datos de varios grupos en un solo gráfico. .pull-left[ Miremos las varaibles salario y los años desde el grado para los profesores. ---- .scroll-box-18[ ```r library(ggplot2) data(Salaries, package="carData") # plot experience vs. salary # (color represents rank, shape represents sex) ggplot(Salaries, aes(x = yrs.since.phd, y = salary, color = rank, shape = sex)) + geom_point(size = 3, alpha = .6) + labs(title = "Academic salary by rank, sex, and years since degree") ``` ] ---- ] .pull-right[ <!-- --> Aun así no es un gran gráfico ya que no se distingue claramente la información. ] --- # <i class="fab fa-delicious" role="presentation" aria-label="delicious icon"></i> Agrupación En la agrupación, los valores de las dos primeras variables se asignan a la x y Y ejes. Luego, las variables adicionales se asignan a otras características visuales como el color, la forma, el tamaño, el tipo de línea y la transparencia. La agrupación le permite trazar los datos de varios grupos en un solo gráfico. .pull-left[ Miremos las varaibles salario y los años desde el grado para los profesores. ---- .scroll-box-18[ ```r library(ggplot2) data(Salaries, package="carData") # plot experience vs. salary # (color represents rank, shape represents sex) ggplot(Salaries, aes(x = yrs.since.phd, y = salary, color = rank, shape = sex)) + geom_point(size = 3, alpha = .6) + labs(title = "Academic salary by rank, sex, and years since degree") ``` ] ---- ] .pull-right[ > Observe la diferencia entre especificar un valor constante `(como size = 3)` y un mapeo de una variable a una característica visual (por ejemplo, `color = rank`). Las asignaciones siempre se colocan dentro de la función `aes`, mientras que la asignación de un valor constante siempre aparece fuera de la función `aes`. ] --- # <i class="fab fa-delicious" role="presentation" aria-label="delicious icon"></i> Agrupación Aquí hay un ejemplo más limpio. Graficaremos la relación entre los años desde el doctorado. y salario usando el tamaño de los puntos para indicar los años de servicio. Esto se llama diagrama de burbujas. .pull-left[ ---- .scroll-box-10[ ```r library(ggplot2) data(Salaries, package="carData") # plot experience vs. salary # (color represents rank and size represents service) ggplot(Salaries, aes(x = yrs.since.phd, y = salary, color = rank, size = yrs.service)) + geom_point(alpha = .6) + labs(title = "Academic salary by rank, years of service, and years since degree") ``` ] ---- Existe una fuerte relación positiva entre los años desde el doctorado, y año de servicio. Los profesores asistentes caen en los años 0-11 desde Ph.D. y rango de servicio de 0-10 años. Claramente, los profesionales altamente experimentados no permanecen en el nivel de Profesor Asistente. No encontramos lo mismo entre prof. asociados y titulares. ] .pull-right[ <!-- --> ] --- # <i class="fab fa-delicious" role="presentation" aria-label="delicious icon"></i> Facetas * La agrupación le permite trazar múltiples variables en un solo gráfico, utilizando características visuales como el color, la forma y el tamaño. * En el facetado, un gráfico consta de varios gráficos separados o pequeños múltiplos , uno para cada nivel de una tercera variable o combinación de variables. ---- .pull-left[ `1.` `facet_wrap()` hace una cinta larga de paneles (generada por cualquier número de variables) y la envuelve en 2D. Esto es útil si tiene una sola variable con muchos niveles y desea organizar los gráficos de una manera más eficiente en cuanto al espacio. * La función `facet_wrap` crea un gráfico independiente para cada nivel de la `variable` dada. La opción `ncol` controla el número de columnas. ```r facet_wrap(~variable, ncol = 1) ``` `facet_wrap(~variable)` devolverá una matriz simétrica de gráficos para el número de niveles de variable. ---- ] .pull-right[ `2.` `facet_grid()` Forma una matriz de paneles definidos por variables de facetas de filas y columnas. Es más útil cuando tiene dos variables discretas y todas las combinaciones de las variables existen en los datos. Puede usar múltiples variables en las filas o columnas, "agregándolas" juntas, por ejemplo a + b ~ c + d. ```r facet_grid( row variable(s) ~ column variable(s)) ``` `facet_grid(.~variable)` devolverá facetas iguales a los niveles de variable distribuido horizontalmente. `facet_grid(variable~.)` Ahora, la distribución es vertical. ---- ] --- # <i class="fab fa-delicious" role="presentation" aria-label="delicious icon"></i> Facetas ejemplos ### Código de facet_wrap ```r # plot salary histograms by rank ggplot(Salaries, aes(x = salary)) + geom_histogram(fill = "cornflowerblue", color = "white") + facet_wrap(~rank, ncol = 1) + labs(title = "Salary histograms by rank") ``` ---- ### Código de facet_grid ```r # plot salary histograms by rank and sex ggplot(Salaries, aes(x = salary / 1000)) + geom_histogram(color = "white", fill = "cornflowerblue") + facet_grid(sex ~ rank) + labs(title = "Salary histograms by sex and rank", x = "Salary ($1000)") ``` --- # <i class="fab fa-delicious" role="presentation" aria-label="delicious icon"></i> Gráfico de facet_wrap <!-- --> --- # <i class="fab fa-delicious" role="presentation" aria-label="delicious icon"></i> Gráfico de facet_grid <!-- --> --- # <i class="fab fa-delicious" role="presentation" aria-label="delicious icon"></i> Agrupación & Facet .pull-left[ ---- .scroll-box-18[ ```r # calculate means and standard erroes by sex, # rank and discipline library(dplyr) plotdata <- Salaries %>% group_by(sex, rank, discipline) %>% summarize(n = n(), mean = mean(salary), sd = sd(salary), se = sd / sqrt(n)) # create better labels for discipline plotdata$discipline <- factor(plotdata$discipline, labels = c("Theoretical", "Applied")) # create plot ggplot(plotdata, aes(x = sex, y = mean, color = sex)) + geom_point(size = 3) + geom_errorbar(aes(ymin = mean - se, ymax = mean + se), width = .1) + scale_y_continuous(breaks = seq(70000, 140000, 10000), label = scales::dollar) + facet_grid(. ~ rank + discipline) + theme_bw() + theme(legend.position = "none", panel.grid.major.x = element_blank(), panel.grid.minor.y = element_blank()) + labs(x="", y="", title="Nine month academic salaries by gender, discipline, and rank", subtitle = "(Means and standard errors)") + scale_color_brewer(palette="Set1") ``` ] ---- ] .pull-right[ <!-- --> ] --- # <i class="fab fa-delicious" role="presentation" aria-label="delicious icon"></i> Agrupación & Facet .pull-left[ ---- .scroll-box-18[ ```r # plot life expectancy by year separately # for each country in the Americas data(gapminder, package = "gapminder") # Select the Americas data plotdata <- dplyr::filter(gapminder, continent == "Americas") # plot life expectancy by year, for each country ggplot(plotdata, aes(x=year, y = lifeExp)) + geom_line(color="grey") + geom_point(color="blue") + facet_wrap(~country) + theme_minimal(base_size = 9) + theme(axis.text.x = element_text(angle = 45, hjust = 1)) + labs(title = "Changes in Life Expectancy", x = "Year", y = "Life Expectancy") ``` ] ---- ] .pull-right[ <!-- --> ] --- name: Maps class: inverse, center, middle # <i class="fa fa-map-marker-alt" role="presentation" aria-label="map-marker-alt icon"></i> # Mapas ---- .right[ .bottom[ #### [<i class="fa fa-bell" role="presentation" aria-label="bell icon"></i>](#menu) ] ] --- # <i class="fa fa-globe-americas" role="presentation" aria-label="globe-americas icon"></i> Mapas Es importante siempre cargar la informaciòn de los .shp o informaciòn de raster. .pull-left[ ---- ```r library(ggplot2) library(sf) # load honey shapefile honey_sf <- read_sf("honey.shp") # get the data for 2008 honey2008 <- honey_sf[honey_sf$year == 2008, ] ggplot(honey2008) + geom_sf() ``` ---- ] .pull-right[ <!-- --> ] --- # <i class="fa fa-globe-americas" role="presentation" aria-label="globe-americas icon"></i> Mapas Es importante siempre cargar la informaciòn de los .shp o informaciòn de raster. .pull-left[ ---- ```r library(ggplot2) library(sf) # load honey shapefile honey_sf <- read_sf("honey.shp") # get the data for 2008 honey2008 <- honey_sf[honey_sf$year == 2008, ] ggplot(data = honey2008) + geom_sf(aes(fill = prcprlb)) + ggtitle(label = "The Honey crisis of 2008", subtitle = "Price per lb") ``` ---- ] .pull-right[ <!-- --> ] --- # <i class="fa fa-globe-americas" role="presentation" aria-label="globe-americas icon"></i> Mapas de coropletas Los mapas de coropletas usan color o sombreado en áreas predefinidas para indicar valores promedio de una variable numérica en esa área. En esta sección usaremos el paquete `choroplethr` para crear mapas que muestren información por país. .pull-left[ `choroplethr` tiene numerosas funciones que simplifican la tarea de crear un mapa de coropletas. Para trazar los datos de la esperanza de vida, usaremos la función `country_choropleth`. * La función requiere que el marco de datos que se va a trazar tenga una columna denominada región y una columna denominada valor. Además, las entradas en la columna de la región deben coincidir exactamente con el nombre de las entradas en la columna de la región del conjunto de datos country.map del paquete choroplethrMaps. ] .pull-right[ ---- ```r data(country.map, package = "choroplethrMaps") head(unique(country.map$region), 12) ``` ``` ## [1] "afghanistan" "angola" "azerbaijan" "moldova" "madagascar" ## [6] "mexico" "macedonia" "mali" "myanmar" "montenegro" ## [11] "mongolia" "mozambique" ``` ---- ] --- # <i class="fa fa-globe-americas" role="presentation" aria-label="globe-americas icon"></i> Mapas de coropletas .pull-left[ Tenga en cuenta que las entradas de la región son todas en minúsculas. Para continuar, necesitamos realizar algunas modificaciones en nuestro conjunto `gapminder` de datos. Específicamente, necesitamos * seleccione los datos de 2007 * cambiar el nombre de la variable de país a región * cambiar el nombre de la variable lifeExp a valor * recodificar los valores de la región a minúsculas * recodifique algunos valores de región para que coincidan con los valores de región en el marco country.map de datos. La función `recode` en el paquete `dplyr` toma la forma `recode(variable, oldvalue1 = newvalue1, oldvalue2 = newvalue2, ...)` ] .pull-right[ ```r # prepare dataset data(gapminder, package = "gapminder") plotdata <- gapminder %>% filter(year == 2007) %>% rename(region = country, value = lifeExp) %>% mutate(region = tolower(region)) %>% mutate(region = recode(region, "united states" = "united states of america", "congo, dem. rep." = "democratic republic of the congo", "congo, rep." = "republic of congo", "korea, dem. rep." = "south korea", "korea. rep." = "north korea", "tanzania" = "united republic of tanzania", "serbia" = "republic of serbia", "slovak republic" = "slovakia", "yemen, rep." = "yemen")) library(choroplethr) country_choropleth(plotdata) ``` ] --- # <i class="fa fa-globe-americas" role="presentation" aria-label="globe-americas icon"></i> Mapas de coropletas <!-- --> --- # <i class="fa fa-globe-americas" role="presentation" aria-label="globe-americas icon"></i> Mapas de coropletas Se puede anexar funciones adicionales de `ggplot2` .pull-left[ ```r country_choropleth(plotdata, num_colors=9) + scale_fill_brewer(palette="YlOrRd") + labs(title = "Life expectancy by country", subtitle = "Gapminder 2007 data", caption = "source: https://www.gapminder.org", fill = "Years") ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-globe-americas" role="presentation" aria-label="globe-americas icon"></i> Mapas de coropletas Población mexicana en Estados Unidos. (Censo 2010) .pull-left[ ```r library(ggplot2) library(choroplethr) data(continental_us_states) # input the data library(readr) mex_am <- read_tsv("3_ggplot2/mexican_american.csv") # prepare the data mex_am$region <- tolower(mex_am$state) mex_am$value <- mex_am$percent # create the map state_choropleth(mex_am, num_colors=9, zoom = continental_us_states) + scale_fill_brewer(palette="YlOrBr") + labs(title = "Mexican American Population", subtitle = "2010 US Census", caption = "source: https://en.wikipedia.org/wiki/List_of_U.S._states_by_Hispanic_and_Latino_population", fill = "Percent") ``` ] .pull-right[ <!-- --> ] --- name: Time class: inverse, center, middle # <i class="fa fa-chart-line" role="presentation" aria-label="chart-line icon"></i> # Gráficos dependientes en el tiempo ---- .right[ .bottom[ #### [<i class="fa fa-bell" role="presentation" aria-label="bell icon"></i>](#menu) ] ] --- # <i class="fa fa-chart-area" role="presentation" aria-label="chart-area icon"></i> Serie temporal .pull-left[ Una serie de tiempo es un conjunto de valores cuantitativos obtenidos en puntos de tiempo sucesivos. Los intervalos entre puntos de tiempo (por ejemplo, horas, días, semanas, meses o años) suelen ser iguales. Considere la serie temporal de Economía que viene con el paquete `gplot2`. Contiene datos económicos mensuales de EE.UU. Recopilados desde enero de 1967 hasta enero de 2015. Tracemos la tasa de ahorro personal (`psavert`). ```r library(ggplot2) ggplot(economics, aes(x = date, y = psavert)) + geom_line() + labs(title = "Personal Savings Rate", x = "Date", y = "Personal Savings Rate") ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-chart-area" role="presentation" aria-label="chart-area icon"></i> Serie temporal Al trazar series de tiempo, asegúrese de que la variable de fecha sea clase `date` y no clase `character`. [Ayuda](https://www.statmethods.net/input/dates.html) .pull-left[ Las marcas de verificación aparecen cada 5 años y las fechas se presentan en formato MMM-YY. La línea de la serie temporal se le da un color rojo apagado y se hace más gruesa, se agrega una línea de tendencia (loess) y se agregan títulos, y el tema se simplifica. .scroll-box-10[ ```r library(ggplot2) library(scales) ggplot(economics, aes(x = date, y = psavert)) + geom_line(color = "indianred3", size=1 ) + geom_smooth() + scale_x_date(date_breaks = '5 years', labels = date_format("%b-%y")) + labs(title = "Personal Savings Rate", subtitle = "1967 to 2015", x = "", y = "Personal Savings Rate") + theme_minimal() ``` ] ] .pull-right[ <!-- --> ] --- # <i class="fa fa-chart-area" role="presentation" aria-label="chart-area icon"></i> Serie temporal .scroll-box-20[ ```r library(quantmod) library(dplyr) # get apple (AAPL) closing prices apple <- getSymbols("AAPL", return.class = "data.frame", from="2021-01-01") apple <- AAPL %>% mutate(Date = as.Date(row.names(.))) %>% select(Date, AAPL.Close) %>% rename(Close = AAPL.Close) %>% mutate(Company = "Apple") # get facebook (FB) closing prices facebook <- getSymbols("FB", return.class = "data.frame", from="2021-01-01") facebook <- FB %>% mutate(Date = as.Date(row.names(.))) %>% select(Date, FB.Close) %>% rename(Close = FB.Close) %>% mutate(Company = "Facebook") # combine data for both companies mseries <- rbind(apple, facebook) # plot data library(ggplot2) ggplot(mseries, aes(x=Date, y= Close, color=Company)) + geom_line(size=1) + scale_x_date(date_breaks = '1 month', labels = scales::date_format("%b")) + scale_y_continuous(limits = c(100, 400), breaks = seq(100, 400, 50), labels = scales::dollar) + labs(title = "NASDAQ Closing Prices", subtitle = "Jan - Jul 2021", caption = "source: Yahoo Finance", y = "Closing Price") + theme_minimal() + scale_color_brewer(palette = "Dark2") ``` ] --- # <i class="fa fa-chart-area" role="presentation" aria-label="chart-area icon"></i> Serie temporal <!-- --> --- # <i class="fa fa-tablets" role="presentation" aria-label="tablets icon"></i> Dummbbell charts .pull-left[ Son útiles para mostrar cambios entre dos puntos de tiempo para varios grupos u observaciones. Se utiliza la función geom_dumbbell del paquete ggalt. Utilizando el conjunto de datos gapminder, tracemos el cambio en la esperanza de vida de 1952 a 2007 en las Américas. El conjunto de datos está en formato long. Tendremos que convertirlo a formato wide. .scroll-box-14[ ```r library(ggalt) library(tidyr) library(dplyr) # load data data(gapminder, package = "gapminder") # subset data plotdata_long <- filter(gapminder, continent == "Americas" & year %in% c(1952, 2007)) %>% select(country, year, lifeExp) # convert data to wide format plotdata_wide <- spread(plotdata_long, year, lifeExp) names(plotdata_wide) <- c("country", "y1952", "y2007") # create dumbbell plot ggplot(plotdata_wide, aes(y = country, x = y1952, xend = y2007)) + geom_dumbbell() ``` ] ] .pull-right[ <!-- --> ] --- # <i class="fa fa-tablets" role="presentation" aria-label="tablets icon"></i> Dummbbell charts ### Reordenando .pull-left[ .scroll-box-20[ ```r library(ggalt) library(tidyr) library(dplyr) # load data data(gapminder, package = "gapminder") # subset data plotdata_long <- filter(gapminder, continent == "Americas" & year %in% c(1952, 2007)) %>% select(country, year, lifeExp) # convert data to wide format plotdata_wide <- spread(plotdata_long, year, lifeExp) names(plotdata_wide) <- c("country", "y1952", "y2007") # create dumbbell plot # create dumbbell plot ggplot(plotdata_wide, aes(y = reorder(country, y1952), x = y1952, xend = y2007)) + geom_dumbbell(size = 1.2, size_x = 3, size_xend = 3, colour = "grey", colour_x = "blue", colour_xend = "red") + theme_minimal() + labs(title = "Change in Life Expectancy", subtitle = "1952 to 2007", x = "Life Expectancy (years)", y = "") ``` ] ] .pull-right[ <!-- --> ] --- # <i class="fa fa-slash" role="presentation" aria-label="slash icon"></i> Pendiente .pull-left[ Cuando hay varios grupos y varios puntos de tiempo, un gráfico de pendiente puede ser útil. Grafiquemos la esperanza de vida de seis países centroamericanos en 1992, 1997, 2002 y 2007. Para crear un gráfico de pendiente, usaremos la función `newggslopegraph` del paquete `CGPfunctions`. <br> 1. Los parámetros de `newggslopegraph` son: * Marco de datos * Variable de tiempo (que debe ser un factor) * Variable numérica a trazar * Variable de agrupación (creando una línea por grupo). ] .pull-right[ ```r library(CGPfunctions) # Select Central American countries data # for 1992, 1997, 2002, and 2007 df <- gapminder %>% filter(year %in% c(1992, 1997, 2002, 2007) & country %in% c("Panama", "Costa Rica", "Nicaragua", "Honduras", "El Salvador", "Guatemala", "Belize")) %>% mutate(year = factor(year), lifeExp = round(lifeExp)) # create slope graph newggslopegraph(df, year, lifeExp, country) + labs(title="Life Expectancy by Country", subtitle="Central America", caption="source: gapminder") ``` ] --- # <i class="fa fa-slash" role="presentation" aria-label="slash icon"></i> Pendiente <img src="3_ggplot2_files/figure-html/unnamed-chunk-168-1.png" width="100%" /> --- # <i class="fa fa-icicles" role="presentation" aria-label="icicles icon"></i> Área .pull-left[ Un gráfico de área simple es básicamente un gráfico lineal, con un relleno desde la línea hasta el eje x. ```r # basic area chart ggplot(economics, aes(x = date, y = psavert)) + geom_area(fill="lightblue", color="black") + labs(title = "Personal Savings Rate", x = "Date", y = "Personal Savings Rate") ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-icicles" role="presentation" aria-label="icicles icon"></i> Área apiladas .pull-left[ Se puede utilizar un gráfico de áreas apiladas para mostrar las diferencias entre grupos a lo largo del tiempo. Trazaremos la distribución por edades de la población estadounidense desde 1900 y 2002. ```r # stacked area chart data(uspopage, package = "gcookbook") ggplot(uspopage, aes(x = Year, y = Thousands, fill = AgeGroup)) + geom_area() + labs(title = "US Population by age", x = "Year", y = "Population in Thousands") ``` ] .pull-right[ <!-- --> ] --- # <i class="fa fa-icicles" role="presentation" aria-label="icicles icon"></i> Área apiladas ### Mejoras .pull-left[ * Cambiar la escala: Simplemente divida la variable Miles por 1000 y repórtelo como Millones. * Crear bordes negros para resaltar la diferencia entre grupos. * Invertir el orden de los grupos para que coincidan con el aumento de edad. * Mejorar el etiquetado. * Elige un esquema de color diferente. * Elija un tema más simple. > Los niveles de la variable `AgeGroup` se pueden invertir usando la función `fct_rev` del paquete `forcats`. ] .pull-right[ ```r # stacked area chart data(uspopage, package = "gcookbook") ggplot(uspopage, aes(x = Year, y = Thousands/1000, fill = forcats::fct_rev(AgeGroup))) + geom_area(color = "black") + labs(title = "US Population by age", subtitle = "1900 to 2002", caption = "source: U.S. Census Bureau, 2003, HS-3", x = "Year", y = "Population in Millions", fill = "Age Group") + scale_fill_brewer(palette = "Set2") + theme_minimal() ``` ] --- # <i class="fa fa-icicles" role="presentation" aria-label="icicles icon"></i> Área apiladas ### Mejoras .pull-left[ <!-- --> ] .pull-right[ > Aparentemente, el número de niños pequeños no ha cambiado mucho en los últimos 100 años. <br> Los gráficos de áreas apiladas son más útiles cuando el interés está tanto en 1. Cambio de grupo a lo largo del tiempo 2. Cambio general en el tiempo. Coloque los grupos más importantes en la parte inferior. Estos son los más fáciles de interpretar en este tipo de trama. ] --- name: Model class: inverse, center, middle # <i class="fa fa-angle-double-right" role="presentation" aria-label="angle-double-right icon"></i> # Modelos estadísticos ---- .right[ .bottom[ #### [<i class="fa fa-bell" role="presentation" aria-label="bell icon"></i>](#menu) ] ] --- # <i class="fab fa-cuttlefish" role="presentation" aria-label="cuttlefish icon"></i> Correlación .left-column[ Un modelo estadístico describe la relación entre una o más variables explicativas y una o más variables de respuesta. <br> `Considere el conjunto de datos de Saratoga Houses, que contiene el precio de venta y las características de las casas del condado de Saratoga, NY en 2006.` ] .right-column[ ```r data(SaratogaHouses, package="mosaicData") # select numeric variables df <- dplyr::select_if(SaratogaHouses, is.numeric) # calulate the correlations r <- cor(df) ``` .scroll-box-14[ <div id="htmlwidget-c1619d5588f37bfa407c" style="width:100%;height:auto;" class="datatables html-widget"></div> <script type="application/json" data-for="htmlwidget-c1619d5588f37bfa407c">{"x":{"filter":"none","extensions":["FixedColumns"],"data":[["price","lotSize","age","landValue","livingArea","pctCollege","bedrooms","fireplaces","bathrooms","rooms"],[1,0.16,-0.19,0.58,0.71,0.2,0.4,0.38,0.6,0.53],[0.16,1,-0.02,0.06,0.16,-0.03,0.11,0.09,0.08,0.14],[-0.19,-0.02,1,-0.02,-0.17,-0.04,0.03,-0.17,-0.36,-0.08],[0.58,0.06,-0.02,1,0.42,0.23,0.2,0.21,0.3,0.3],[0.71,0.16,-0.17,0.42,1,0.21,0.66,0.47,0.72,0.73],[0.2,-0.03,-0.04,0.23,0.21,1,0.16,0.25,0.18,0.16],[0.4,0.11,0.03,0.2,0.66,0.16,1,0.28,0.46,0.67],[0.38,0.09,-0.17,0.21,0.47,0.25,0.28,1,0.44,0.32],[0.6,0.08,-0.36,0.3,0.72,0.18,0.46,0.44,1,0.52],[0.53,0.14,-0.08,0.3,0.73,0.16,0.67,0.32,0.52,1]],"container":"<table class=\"display\">\n <thead>\n <tr>\n <th> <\/th>\n <th>price<\/th>\n <th>lotSize<\/th>\n <th>age<\/th>\n <th>landValue<\/th>\n <th>livingArea<\/th>\n <th>pctCollege<\/th>\n <th>bedrooms<\/th>\n <th>fireplaces<\/th>\n <th>bathrooms<\/th>\n <th>rooms<\/th>\n <\/tr>\n <\/thead>\n<\/table>","options":{"dom":"t","scrollX":true,"scrollCollapse":true,"columnDefs":[{"className":"dt-right","targets":[1,2,3,4,5,6,7,8,9,10]},{"orderable":false,"targets":0}],"order":[],"autoWidth":false,"orderClasses":false}},"evals":[],"jsHooks":[]}</script> ] ] --- # <i class="fab fa-cuttlefish" role="presentation" aria-label="cuttlefish icon"></i> Correlación La función `ggcorrplot` del paquete `ggcorrplot` se puede utilizar para visualizar estas correlaciones. .pull-left[ ```r library(ggplot2) library(ggcorrplot) ggcorrplot(r) ``` ] .pull-right[ <!-- --> ] --- # <i class="fab fa-cuttlefish" role="presentation" aria-label="cuttlefish icon"></i> Correlación `ggcorrplot` tiene varias opciones para personalizar la salida. Por ejemplo: .pull-left[ * `hc.order = TRUE` reordena las variables, colocando juntas las variables con patrones de correlación similares. * `type = "lower"` traza la parte inferior de la matriz de correlación. * `lab = TRUE` superpone los coeficientes de correlación (como texto) en el gráfico. ```r ggcorrplot(r, hc.order = TRUE, type = "lower", lab = TRUE) ``` ] .pull-right[ <!-- --> ] --- # <i class="fab fa-reddit-alien" role="presentation" aria-label="reddit-alien icon"></i> Regresión lineal .pull-left[ Considere la predicción de los precios de las viviendas en el conjunto de datos de Saratoga según el tamaño del lote (pies cuadrados), la edad (años), el valor del terreno (miles de dólares), el área habitable (pies cuadrados), la cantidad de dormitorios y baños y si la casa está frente al mar. o no. ---- ```r data(SaratogaHouses, package="mosaicData") houses_lm <- lm(price ~ lotSize + age + landValue + livingArea + bedrooms + bathrooms + waterfront, data = SaratogaHouses) summary(houses_lm) ``` ---- ] .pull-right[ ``` ## ## Call: ## lm(formula = price ~ lotSize + age + landValue + livingArea + ## bedrooms + bathrooms + waterfront, data = SaratogaHouses) ## ## Residuals: ## Min 1Q Median 3Q Max ## -220208 -35416 -5443 27570 464320 ## ## Coefficients: ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) 1.399e+05 1.647e+04 8.491 < 2e-16 *** ## lotSize 7.501e+03 2.075e+03 3.615 0.000309 *** ## age -1.360e+02 5.416e+01 -2.512 0.012099 * ## landValue 9.093e-01 4.583e-02 19.841 < 2e-16 *** ## livingArea 7.518e+01 4.158e+00 18.080 < 2e-16 *** ## bedrooms -5.767e+03 2.388e+03 -2.414 0.015863 * ## bathrooms 2.455e+04 3.332e+03 7.366 2.71e-13 *** ## waterfrontNo -1.207e+05 1.560e+04 -7.738 1.70e-14 *** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## Residual standard error: 59370 on 1720 degrees of freedom ## Multiple R-squared: 0.6378, Adjusted R-squared: 0.6363 ## F-statistic: 432.6 on 7 and 1720 DF, p-value: < 2.2e-16 ``` ] --- # <i class="fab fa-reddit-alien" role="presentation" aria-label="reddit-alien icon"></i> Regresión lineal El paquete `visreg` proporciona herramientas para visualizar estas relaciones condicionales. .pull-left[ La función `visreg` toma (1) el modelo y (2) la variable de interés y traza la relación condicional, controlando las otras variables. La opción `gg = TRUE` se usa para producir un gráfico `ggplot2`. ---- ```r # conditional plot of price vs. living area library(ggplot2) library(visreg) visreg(houses_lm, "livingArea", gg = TRUE) ``` ---- ] .pull-right[ <!-- --> ] --- # <i class="fab fa-reddit-alien" role="presentation" aria-label="reddit-alien icon"></i> Regresión lineal .pull-left[ Observemos la diferencia de precio entre las viviendas frente al mar y las que no lo son, controlando las otras siete variables. ---- ```r # conditional plot of price vs. waterfront location visreg(houses_lm, "waterfront", gg = TRUE) + scale_y_continuous(label = scales::dollar) + labs(title = "Relationship between price and location", subtitle = "controlling for lot size, age, land value, bedrooms and bathrooms", caption = "source: Saratoga Housing Data (2006)", y = "Home Price", x = "Waterfront") ``` ---- > Hay muchas menos casas en el agua y tienden a ser más caras (incluso controlando el tamaño, la edad y el valor de la tierra). ] .pull-right[ <!-- --> ] --- # <i class="fab fa-confluence" role="presentation" aria-label="confluence icon"></i> Regresión logística Usando los datos de CPS85, observemos las probabilidades de estar casado, según el sexo, la edad, la raza y el sector laboral. .pull-left[ ---- .scroll-box-14[ ```r # fit logistic model for predicting # marital status: married/single data(CPS85, package = "mosaicData") cps85_glm <- glm(married ~ sex + age + race + sector, family="binomial", data=CPS85) # plot results library(ggplot2) library(visreg) visreg(cps85_glm, "age", gg = TRUE, scale="response") + labs(y = "Prob(Married)", x = "Age", title = "Relationship of age and marital status", subtitle = "controlling for sex, race, and job sector", caption = "source: Current Population Survey 1985") ``` ] ---- > La opción `scale = "response"` crea una gráfica basada en una escala de probabilidad (en lugar de log-odds). ] .pull-right[ 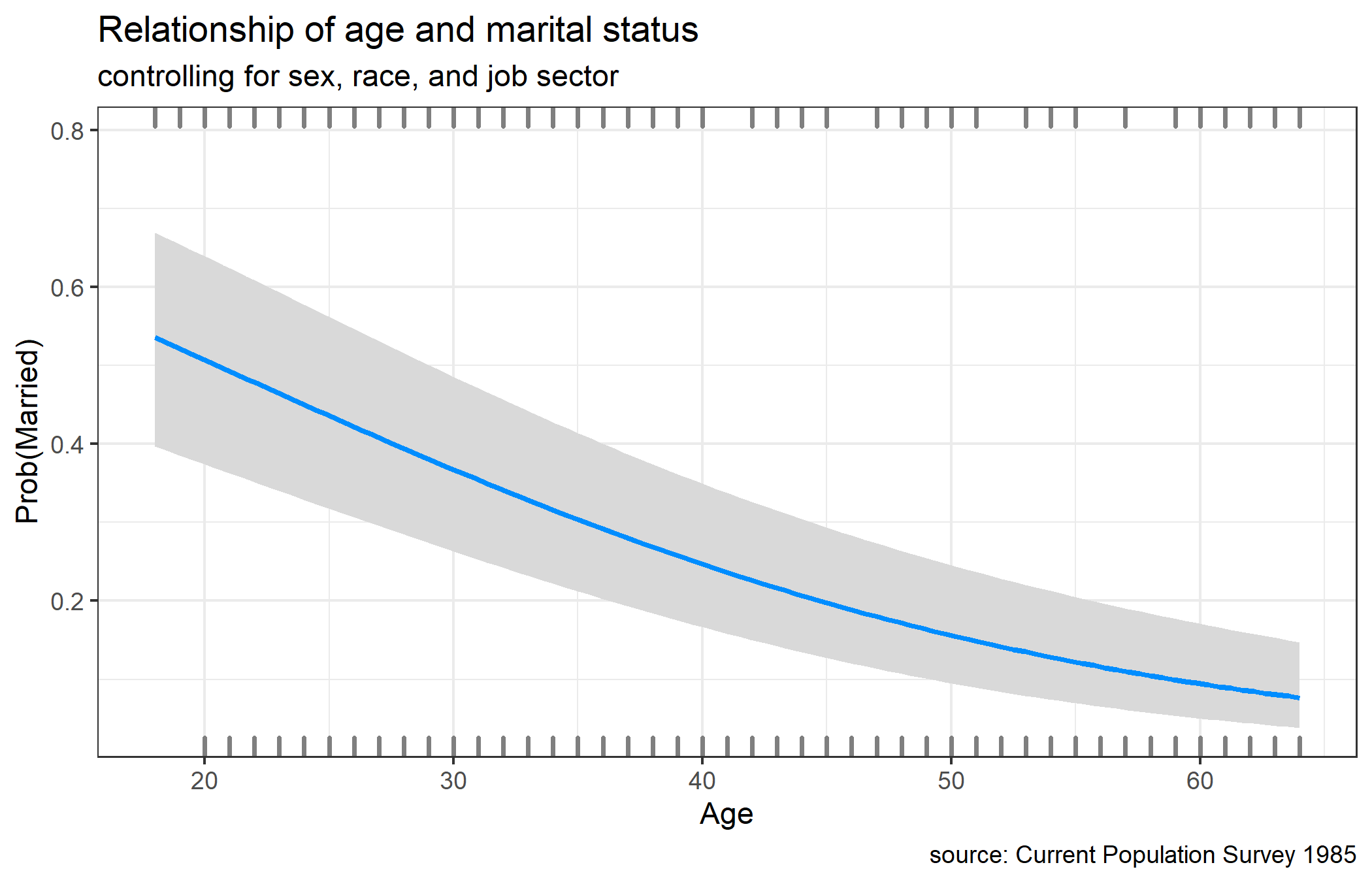<!-- --> Se estima que la probabilidad de estar casado es de aproximadamente 0,5 a los 20 años y disminuye a 0,1 a los 60 años, controlando las otras variables. ] --- # <i class="fab fa-confluence" role="presentation" aria-label="confluence icon"></i> Regresión logística Podemos crear múltiples gráficos condicionales agregando una opción `by`. .pull-left[ El siguiente código trazará la probabilidad de casarse por edad, por separado para hombres y mujeres, controlando por raza y sector laboral. ---- .scroll-out-14[ ```r # plot results library(ggplot2) library(visreg) visreg(cps85_glm, "age", by = "sex", gg = TRUE, scale="response") + labs(y = "Prob(Married)", x = "Age", title = "Relationship of age and marital status", subtitle = "controlling for race and job sector", caption = "source: Current Population Survey 1985") ``` ] ---- ] .pull-right[ <!-- --> ] --- class: inverse, center, middle .pull-left[ .center[ <br><br> # Gracias!!! <br><br><br><br><br> ### ¿Preguntas? ] ] .pull-right[ <img style="border-radius: 50%;" src="img/avatar.png" width="150px" /> ### [www.joaquibarandica.com](https://www.joaquibarandica.com) <i class="fab fa-twitter" role="presentation" aria-label="twitter icon"></i> jotajb5 <i class="fab fa-github" role="presentation" aria-label="github icon"></i> juniorjb5 <i class="fa fa-envelope" role="presentation" aria-label="envelope icon"></i> orlando.joaqui@correounivalle.edu.co ] <br><br><br> ---- *Las imágenes utilizadas para ambientar la presentación son de [pixabay](https://pixabay.com/).* Sources: [R for the Rest of Us](https://rfortherestofus.com/), Rob Kabacoff, Nico Hahn